早期语言模型与 RNN
首先需要明确什么是语言模型。广义来说语言模型就是一个进行 next-token-prediction 的模型。也就是说给定一段文本,语言模型的任务是预测下一个最有可能出现的 token 是什么。为了实现这一目的,一些早期的尝试包括使用简单粗暴的统计模型11 例如 n-gram 模型,它通过统计前 n-1 个 token 出现时第 n 个 token 出现的频率来进行预测。、建立简单的神经网络预测模型等。但是这些方法都存在一定的局限性:他们往往都做出对文本的马尔可夫假设22 马尔可夫假设认为当前状态只与前一个状态有关,而与更早的状态无关。在语言模型中,这意味着预测下一个 token 只考虑前面有限个 token。,忽略了文本中长期依赖关系的重要性,而这一点在自然语言处理中是非常频繁而关键的。
RNN (Recurrent Neural Network)
传统的语言模型在处理序列数据时存在局限性,只能利用有限的上下文信息。RNN 的提出旨在解决这一问题,它具备处理任意长度输入序列的能力,并能利用整个历史上下文来对当前时刻进行预测。 RNN 的核心思想是在不同的时间步重复使用相同的参数矩阵,从而使得模型参数量独立于输入序列的长度。
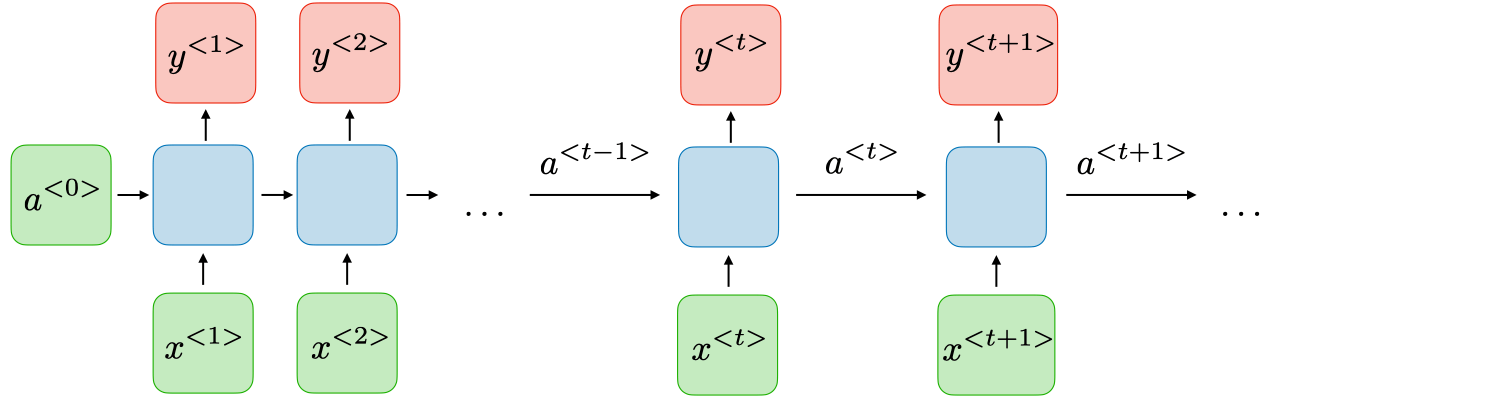
在时间步 ,RNN 接收输入词向量 和上一时刻的隐藏状态 ,计算当前的隐藏状态 和输出概率分布 。其数学定义如下:
其中:
- :时刻 的输入词向量。
- :时刻 的隐藏层状态,充当模型的“记忆”。
- :用于传递历史信息的权重矩阵。
- :用于处理当前输入的权重矩阵。
- :用于输出预测的权重矩阵( 为词表大小)。
- :激活函数
注意这个结构具有的一个有趣的特性:它的参数在所有时间步都是共享的。这意味着无论输入序列有多长,模型的参数量都是固定的,不会随着序列长度的增加而增加。这种参数共享机制使得 RNN 能够处理变长的输入序列,同时也减少了模型的复杂度。
RNN 的训练
RNN 通常使用交叉熵误差作为损失函数。对于单个时间步 ,假设真实词为 (one-hot 向量),损失定义为:
对于整个序列而言的总损失为:
我们先来看对于梯度下降算法而言最重要的,关于参数矩阵的梯度。由于 RNN 的参数在所有时间步都是共享的,我们不能简单地将每个时间步的矩阵看作是独立的参数。因此,在计算梯度时,我们需要将所有时间步的梯度进行累加: 指的是将时间步 的 视为独立参数时的梯度
这可以将最终的损失函数看成对于多个参数矩阵的函数 ,然后利用一阶微分的线性性质进行累加。由此一来我们只需在反向传播时使用所谓 BPTT(Backpropagation Through Time)算法,将误差从最后一个时间步反向传播到第一个时间步,累加每个时间步的梯度即可。利用链式法则,我们可以得到:
这里指代任意一个参数矩阵
这其中就包含了从时间步 反向传播到时间步 的梯度 ,这也是 RNN 训练中最为关键的部分。我们进一步展开 :
这里 是一个对角矩阵,其对角线元素为激活函数 在输入 处的导数。通过这个展开式我们可以看到,随着时间步差距 的增加,梯度 会经历多次矩阵乘法,这就可能导致梯度爆炸或梯度消失的问题。
其中 和 分别是矩阵 和激活函数 的 L2 范数上界。如果 ,那么随着 的增加,梯度将会指数级地减小,导致梯度消失。这也就意味着,来自长程的信息无法有效传递到当前时间步,模型难以学习到长期依赖关系。
相反,指数级的梯度相乘也可能导致梯度爆炸的问题,使得模型参数更新过大,训练过程不稳定。这对于 RNN 的训练是十分不利的,因此在实际应用中,通常会采用梯度裁剪(gradient clipping)等技术来缓解梯度爆炸的问题:
if norm(grad) > threshold:
grad = grad / norm(grad) * threshold缓解梯度消失的问题有一个较为简单的方法:那就是使用 ReLU 等不易饱和的激活函数,从而减小 的值。不过更为有效的方法是引入门控机制(gating mechanism),这也是后续 LSTM 和 GRU 等变种 RNN 的核心思想。
门控的 RNN 变种: GRU 与 LSTM
首先需要明确什么是“门”(Gate),以及为何需要引入门控机制。数学上,它是一个 sigma 函数(输出 0 到 1 之间的值)和一个点乘操作的组合。门控机制的核心思想是通过“门”来控制信息的流动,从而有选择地保留或遗忘某些信息。在经典的 RNN 结构中,每次更新时,整个隐藏状态都会经过非线性变换和矩阵乘法。这意味着模型没有机制来决定“保留”之前的某个特定信息,每一步都在重写记忆。门控结构赋予模型选择性读写的能力:模型应当自主学习何时更新记忆、何时遗忘旧信息、何时保持现状。
GRU (Gated Recurrent Unit)
GRU 通过两个门控信号来控制信息流:
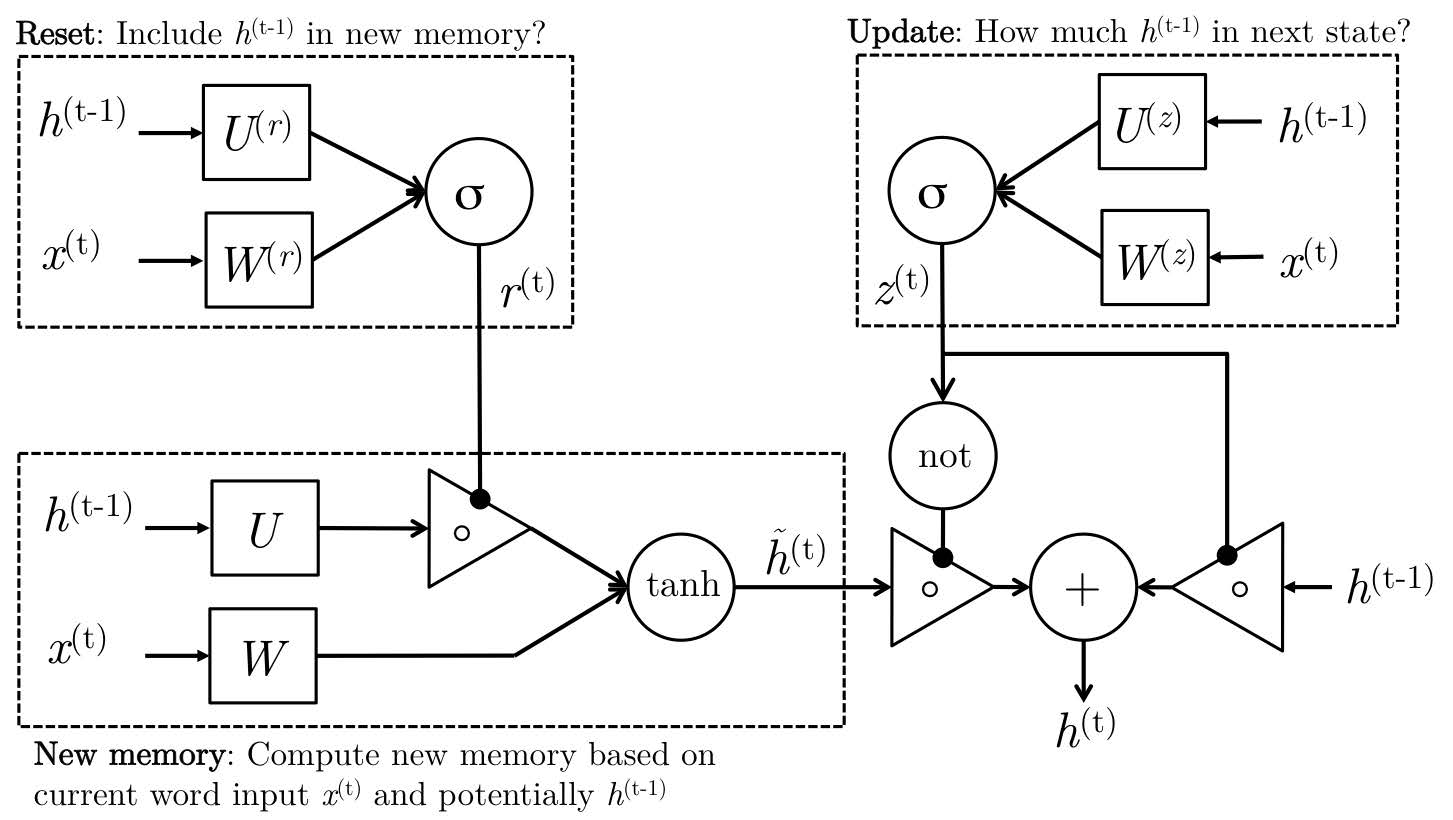
更新门 (): 这是 GRU 最重要的设计。 决定了有多少旧的记忆 被直接复制到当前状态 。
- 如果 ,则 。这意味着过去的记忆被几乎完好无损地保存了下来,且梯度可以跳过非线性变换直接回传。这模拟了“长期记忆”。
- 如果 ,则模型忽略过去,主要使用新计算的记忆 。
重置门 (): 它负责判断计算当前的新内容时,旧的记忆有多重要。
- 如果 ,旧隐藏状态 被屏蔽,候选记忆 仅依赖于当前输入 。这允许模型“重置”其状态,去捕捉短期内的模式变化。
候选记忆 (): 这是在考虑了当前输入和(被重置门过滤后的)过去上下文后,生成的新信息摘要。33 会先经过 tanh 非线性变换,这主要是为了限制其值域,防止数值过大而导致梯度爆炸
GRU 的设计使得模型能够灵活地在长期记忆和短期记忆之间切换,从而更好地捕捉序列数据中的复杂依赖关系。通过门控机制,GRU 能够有效缓解梯度消失问题,使得信息能够跨越更长的时间步进行传递。
LSTM (Long Short-Term Memory)
LSTM 的结构比 GRU 更加复杂,它单独引入了用于模拟长期记忆的“细胞状态”(cell state)。
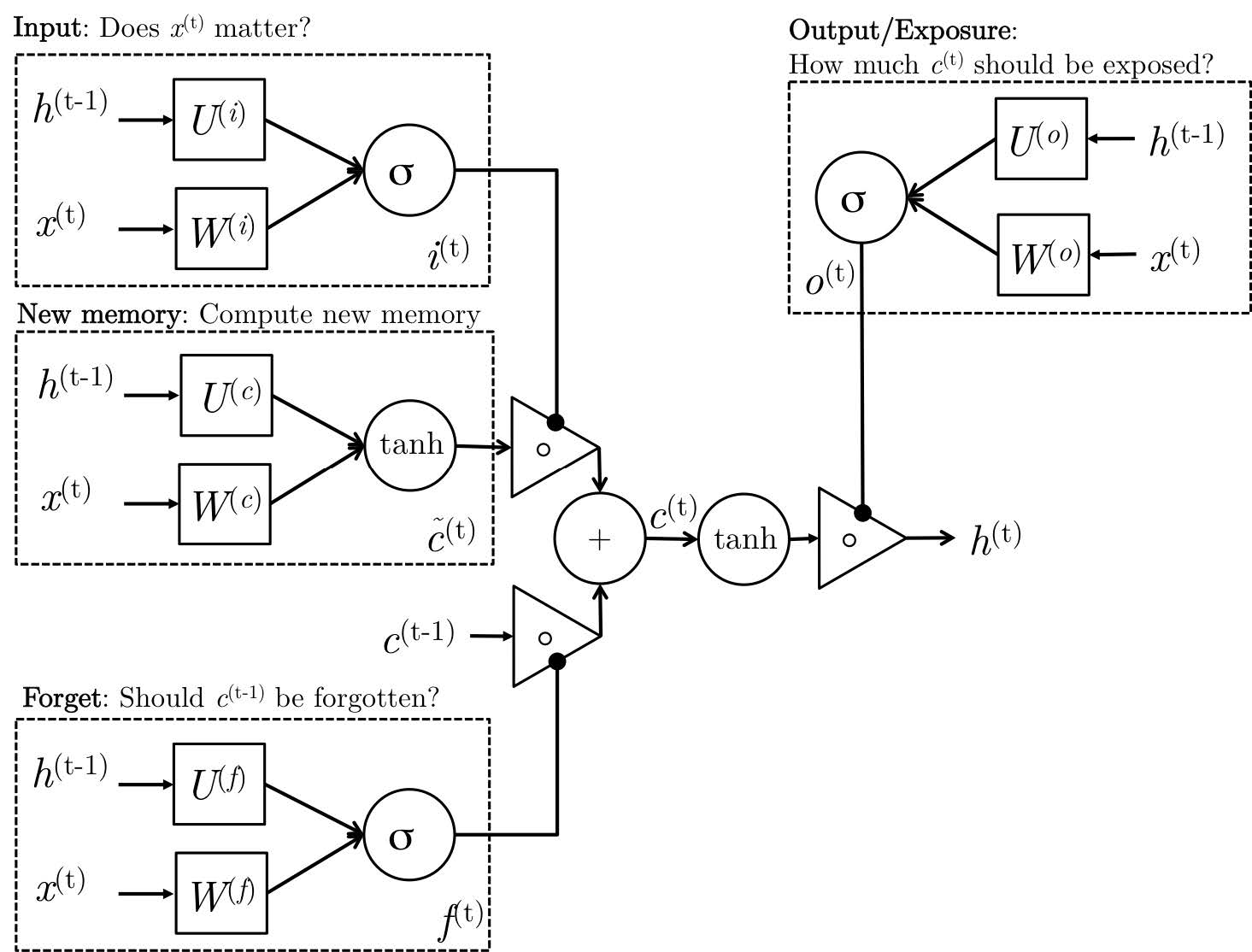
LSTM 拥有三个门控变量,分别控制信息的流入、流出和遗忘:
遗忘门 :之前的上下文 可能包含已经过时的信息。例如,句子结束了,之前的语境不再重要。 决定了保留多少旧细胞状态。,如果 ,则表示遗忘大部分旧信息。
输入门 :决定了当前的候选细胞状态 有多少被写入到最终的细胞状态 中。,如果 ,则表示大量新信息被写入。
输出门 :控制最终的隐藏状态 中包含多少细胞状态的信息。通过 ,模型可以选择性地输出细胞状态的内容。
LSTM 最独特的设计就是它显式地通过一个单独的 cell state 来存储长期记忆。在更新 时包含了关于老信息的线性传递路径 ,这使得梯度可以直接通过细胞状态进行反向传播,而不会经过非线性变换,受到的干扰很少(只有门允许时才变),变化比较缓慢,从而有效缓解了梯度消失问题。而隐藏状态()则更多地用于捕捉短期动态信息。它非常敏感,每一步都会剧烈变化,用于应对当前的即时输出任务。这种显式的长期记忆和短期记忆的分离,使得 LSTM 拥有长期的记忆通道以及短期的动态响应能力。