PPO算法:原理与实现
原始的 REINFORCE 算法存在几个严重问题。
- 梯度估计方差很高:由于我们只能采样有限数量的输出来估计梯度,估计结果可能很不稳定。
- 训练过程也可能不稳定:参数更新可能导致模型行为剧烈变化。
- 样本效率较低。
Proximal Policy Optimization(PPO)11 Schulman et al., 2017是 OpenAI 在 2017 年提出的一种强化学习算法,旨在解决上述问题。PPO 的核心思想是:限制每次更新中策略的变化幅度,防止模型“走得太远”。通过引入裁剪机制和优势函数估计,PPO 能够在保持训练稳定性的同时,提高样本效率。在LLM的训练中,PPO被广泛应用于RLHF(Reinforcement Learning with Human Feedback)阶段,用于优化语言模型的生成质量。理解PPO的原理和实现细节对于深入掌握LLM的训练过程至关重要。接下来,我们将系统介绍PPO算法的核心要素、优势估计方法以及在LLM中的具体应用流程。
方差问题与基线(Baseline)
为什么 REINFORCE 的方差很高?直观来说,假设我们采样了 个样本,其中一些获得了高奖励,一些获得了低奖励。由于每个样本的梯度都依赖于其获得的奖励,而奖励的绝对值取决于奖励函数的“零点”,这可能导致梯度方向不稳定。
解决这一问题的方法是引入基线(baseline)。我们不直接使用奖励 ,而是使用 。只要基线 不依赖于当前策略参数(或者说与 无关),这种修改不会改变梯度的期望值:
由于 ,第二项为0。因此,选择合适的基线可以降低方差而不改变梯度的期望值。
一个常用的基线选择是价值函数 ,它估计从状态 开始的期望累积奖励。使用 作为基线,得到的 被称为优势函数(Advantage Function),它衡量采取某个动作相对于“平均水平”的好坏程度。
重要性采样
PPO 的另一个关键思想是重要性采样(Importance Sampling)。在强化学习中,我们需要在当前策略 下采样的数据来估计梯度。但如果每次更新都完全重新采样,数据利用效率会很低。
重要性采样允许我们用旧策略 采样的数据来估计新策略 的期望:
这个技巧使我们能够复用之前采样的数据,但代价是引入了方差——当新旧策略差异较大时,重要性采样的估计会变得不稳定。
PPO的裁剪目标
Proximal Policy Optimization(PPO)22 Schulman et al., 2017通过引入裁剪机制解决了这些问题。PPO的核心思想是:限制每次更新中策略的变化幅度,防止模型“走得太远”。
PPO使用以下裁剪目标函数:
这里 是新旧策略的概率比, 是优势函数(表示这个输出比平均水平好多少)。优势函数 ,衡量采取动作 相对于平均水平的额外收益。
是裁剪范围(比如0.2)。
让我们详细理解这个目标函数。考虑两种情况:
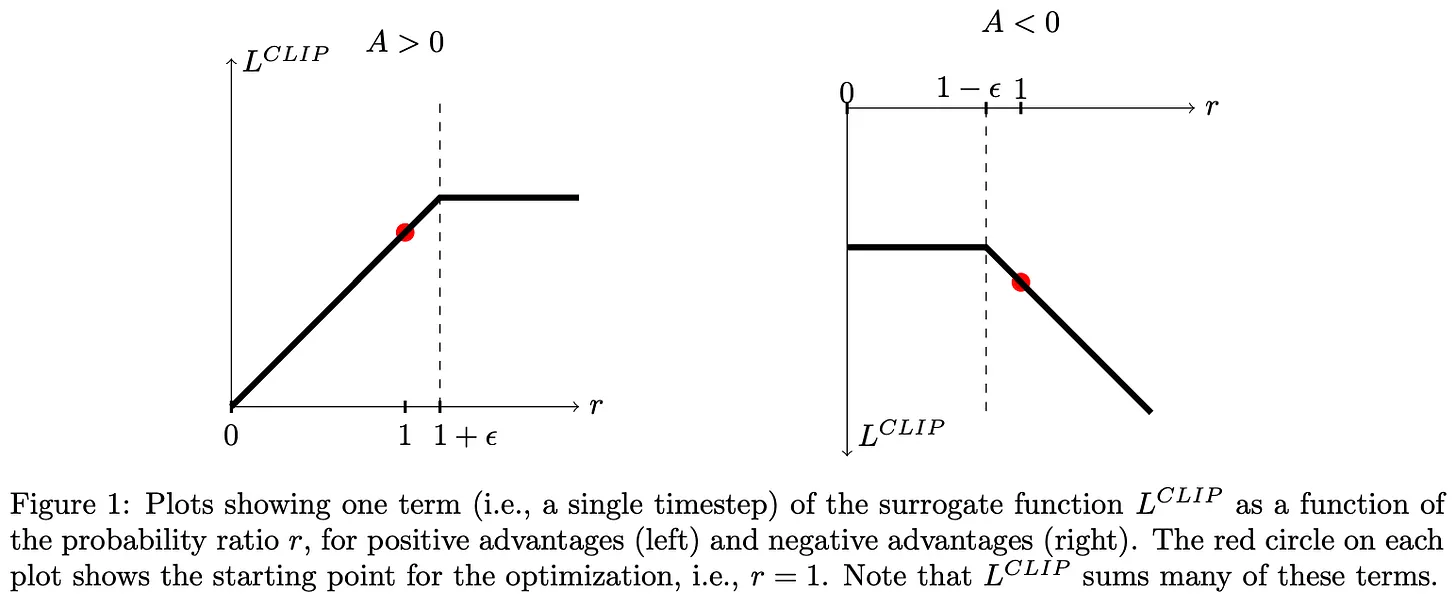
优势函数 (即当前样本比平均水平好):我们希望增加生成它的概率,即增加 。如果没有裁剪,目标会鼓励尽可能增大 。但 clip 函数将 限制在 以内,所以最多只能增加 倍。
优势函数 (即当前样本比平均水平差):我们希望减少生成它的概率,即减小 。裁剪将 限制在 以内,所以最多只能减少到 倍。
“clip”函数的直觉是:它把概率比限制在 区间内。这意味着:即使新策略认为某个输出特别好(概率比很高),我们也不让它变化太多。这保证了训练过程的稳定性。PPO 还有另一个版本叫做 PPO-Byte,用于连续动作空间,它使用 KL 散度作为惩罚项而不是裁剪。
优势函数与TD误差
在深入 GAE 之前,我们需要先理解两个关键概念:优势函数和时序差分(TD)误差。这是理解 GAE 构造思路的基础。
为什么要用优势函数?
回想一下,在之前的讨论中,我们使用基线 来降低方差:使用 而不是直接使用 。一个自然的疑问是:为什么不直接用奖励 ,而要引入“优势函数”这个概念?
原因在于,我们之前讨论的奖励 通常是“即时奖励”——只衡量当前这一步的好坏。但在很多场景中,一个动作的好坏不仅取决于当前这一步的奖励,还取决于它对未来奖励的影响。
举例来说,假设你在玩一个策略游戏。在某一回合,你选择了一个动作,这个动作在当前回合只获得了较低的分数,但它为后续回合创造了巨大的优势。如果你只看即时奖励,你会认为这是一个“坏”动作。但实际上,这是一个“好”动作,因为它带来了长远的收益。
优势函数正是为了解决这个问题而引入的。形式上,优势函数定义为:
这里的 是动作价值函数,表示从状态 采取动作 后,按照策略 继续下去能获得的期望总奖励。而 是状态价值函数,表示从状态 开始,按照策略 继续下去能获得的期望总奖励。
两者的差值 表示:采取动作 相比于“平均水平”好多少。如果 ,说明这个动作比平均水平好;如果 ,说明这个动作比平均水平差。
这就是优势函数的直观含义:它衡量的是某个动作相对于“默认行为”(按照价值函数 估计的平均水平)的优劣程度。
时序差分(TD)误差
现在,让我们来看看如何估计优势函数。一个最直接的想法是使用蒙特卡洛(MC)方法:通过采样完整的轨迹,计算从当前时刻到最终的累积奖励,然后减去基线。
具体来说,从时刻 开始的累积回报(return)定义为:
我们可以把 看作是对 的一个估计。然后优势函数可以估计为 。
然而,蒙特卡洛方法有一个问题:它需要等到整个轨迹结束才能计算,效率较低。而且,由于 是通过采样得到的,估计的方差可能很高。
有没有一种方法,可以在不等到轨迹结束的情况下,估计当前状态的价值?这就是时序差分(Temporal Difference, TD)方法的核心思想。
TD 方法利用贝尔曼方程的递归性质。回忆一下,状态价值函数满足:
这意味着:当前状态的价值 = 即时奖励的期望 + 折扣后未来状态价值的期望。
如果我们用 来估计当前状态的价值,用 来估计“即时奖励 + 折扣后的未来价值”,两者的差值就是 TD 误差:
这个式子的直觉解释是:
- 是我们“观察到”的回报(用当前的价值估计来近似未来价值)
- 是我们“预测的”当前价值
- 两者的差值 表示我们的预测“错了多少”
如果 ,意味着实际情况比我们预测的要好,我们应该增加 的估计;反之,如果 ,我们应该减少估计。
这就是 TD 学习的核心思想:通过不断修正“预测误差”来学习价值函数。
从TD误差到优势函数
现在,关键的洞察来了:TD 误差 实际上与优势函数有密切关系! 从定义出发:
而根据贝尔曼方程, 函数满足:
如果我们用 的采样来近似期望,就得到:
也就是说,TD 误差 是优势函数 的一个单步估计。 这是一个非常重要的洞见。它告诉我们:我们可以不用等到轨迹结束,而是通过每一步的 TD 误差来估计优势。
广义优势估计(GAE)的构造思路
现在我们已经理解了 TD 误差,接下来就可以理解 GAE 是如何构造的了。
理想的优势函数应该是:从当前时刻开始,所有未来 TD 误差的加权和。
为什么?因为每一个 TD 误差 都包含了关于“从时刻 开始的额外收益”的信息。把这些信息累积起来,就能得到对优势函数的更好估计。
具体来说,如果我们把多个连续步骤的 TD 误差加起来:
继续推广,我们可以得到:
这就是 广义优势估计(Generalized Advantage Estimation, GAE)!
其中 是一个超参数,用于控制我们考虑多远的未来。
为什么这样构造?
让我们理解一下 GAE 的构造逻辑:
当 时:
只考虑当前这一步的 TD 误差。这相当于只比较当前动作与“当前状态下的平均动作”。
- 优点:方差很低(因为只依赖当前的采样)
- 缺点:偏差可能很高(因为只用一步来估计长期优势)
当 时:
考虑所有未来步骤的 TD 误差的加权和。这实际上等价于蒙特卡洛方法!
- 优点:偏差很低(因为累积了所有未来信息)
- 缺点:方差很高(因为依赖长轨迹的采样)
通过调节 ,我们可以在偏差和方差之间取得平衡。这就是 GAE 的核心思想。
GAE在PPO中的作用
在 PPO 算法中,GAE 扮演着至关重要的角色。我们使用 GAE 来计算每个时间步的优势函数估计 ,然后用这个优势函数来指导策略更新。
具体来说,PPO 的目标函数(之前我们看到的裁剪目标)中的 就是用 GAE 计算出来的。通过选择合适的 (通常在 0.9 到 0.99 之间),PPO 能够在保持训练稳定性的同时,充分利用长期回报的信息。
这就是为什么 GAE 是 PPO 在实践中效果良好的关键技巧之一。它提供了一种灵活、可调的方法来平衡估计的偏差和方差,使得策略梯度方法能够在复杂的语言模型训练中稳定工作。
PPO算法的具体流程
在LLM的训练中,PPO的应用场景与传统强化学习(如游戏AI或机器人控制)有着本质区别。最大的不同在于“环境”的定义:在LLM中,环境不再是物理世界或游戏模拟器,而是由奖励模型(Reward Model)和语言模型本身共同构成的虚拟环境。具体来说,LLM的每一个生成步骤都是一个动作,而整个生成过程就是由一系列动作组成的轨迹。这种设定带来了独特的挑战:首先,一个生成序列可能包含上千个token,这意味着horizon长度T非常大;其次,真正的奖励信号通常只在序列结束时才会出现——只有在生成了完整的回答后,奖励模型才能对整体质量进行评分;最后,我们需要同时加载四个大模型到显存中:Actor模型(正在训练的策略网络)、Reference模型(SFT模型的冻结副本,用于计算KL散度防止模型崩坏)、Critic模型(预测价值)和Reward模型(给出最终奖励)。这些因素使得LLM中的PPO训练在工程实现上极具挑战性。
PPO中的四个模型
在深入算法流程之前,我们需要先理解PPO训练中涉及的四个神经网络模型,它们各自扮演不同的角色。
- 第一个是Actor模型 ,这是我们要训练的主角,也就是当前的LLM。它的输入是prompt,输出是下一个token的概率分布。我们的目标是通过训练让Actor模型生成更好的回答。
- 第二个是Reference模型 ,这是SFT(Supervised Fine-Tuning)模型的冻结副本,参数在训练过程中不会更新。它的作用是计算KL散度,作为正则化项防止Actor模型在训练过程中过度优化而忘记了原始的语言能力。
- 第三个是Critic模型 ,它的任务是预测当前生成的序列“大概能得多少分”,输入是prompt加上已生成的token序列,输出是一个标量数值。Critic模型通常由Reward模型初始化,但它会随着PPO训练而不断更新,以便更准确地估计价值。
- 第四个是Reward模型 ,它是整个系统的“裁判”,是一个完全冻结的模型。Reward模型的输入是完整的prompt和response,输出是一个标量分数(比如1.0到5.0),衡量这个回答的质量。
第一步:采样(Rollout Generation)
训练循环的第一步是让Actor模型生成一批数据。具体来说,我们从训练数据集中随机抽取一批prompt,记为,然后使用当前策略自回归地生成回答。假设回答由个token组成,即。在生成过程中,我们需要保存完整的生成序列以及对应的log概率,即保存元组。这些数据被称为“旧策略”产生的数据,因为它们是在参数更新之前生成的。需要注意的是,这里的“状态”实际上是,即在时刻时已经生成的上下文;“动作”就是生成的token。这种状态定义与传统的强化学习非常不同:在游戏AI中,状态是游戏画面的像素;而在LLM中,状态是已经生成的文本序列。
第二步:计算混合奖励(Hybrid Reward Computation)
这是LLM PPO中最特殊也最关键的一步。我们不仅要看“回答好不好”(Reward Model给出的分数),还要看“回答是否偏离了原始语言模型”(KL散度惩罚)。对于每个生成的token位置,即时奖励由两部分组成。如果(即不是最后一个token),奖励只包含KL惩罚项:
这里是KL惩罚系数,通常在0.01到0.1之间,用于控制约束的力度。如果(即最后一个token),奖励是Reward Model给出的分数减去KL惩罚:
这种设计的直觉是:Reward Model只在完整序列生成后才能给出评价,所以我们将这个分数加在最后一个token上;而KL惩罚在每个token位置都计算,这是为了持续约束策略不要偏离Reference模型太远。如果Actor生成了一个Reference模型认为概率很低的词,概率比值会变大,变成负数,奖励降低(即受到惩罚)。这种机制确保了模型在优化奖励的同时,不会完全丧失原有的语言能力。
实际上,KL散度可以写成更完整的形式。对于两个分布和,它们的KL散度为:
但在实际训练中,我们只需要计算当前生成的token的KL贡献,这正是上面公式中的对数项。
第三步:优势估计(Advantage Estimation)
有了奖励序列和价值序列(由Critic模型预测),我们就可以计算优势函数。依然使用之前介绍的GAE(广义优势估计)方法。首先计算TD误差:
然后通过GAE公式得到优势:
这里的一个直观理解是:意味着在第步生成的token比Critic预期的要好——要么是因为Reward Model最终给分高,要么是因为这个token符合Reference模型的分布(KL惩罚小)。反之,如果,说明这个token选择得不好。在LLM场景中,由于真正的奖励只在最后一步出现,前面的优势主要依赖于Critic的价值预测回传,这使得Critic的准确性变得尤为重要。
第四步:策略优化(Policy Optimization)
现在我们有了数据(states, actions, old log probabilities)、优势函数和奖励,可以开始优化Actor和Critic的参数了。这一步通常会重复个epoch(通常取4到10),即同一批数据会被多次使用。
对于Actor模型,我们需要计算当前策略与采样时策略的概率比率:
然后使用PPO的核心裁剪目标:
其中通常是0.2。这个公式的直觉是:如果(这个词选得好),我们要提高它的概率(即增大),但不能超过;如果(这个词选得不好),我们要降低概率,但不能低于。这种裁剪机制保证了策略更新的稳定性,防止因为某一批数据的奖励特别高就过度调整策略。
对于Critic模型,目标是最小化价值预测误差:
注意,这里的目标值是,这是对真实回报的一个经过GAE修正后的估计。总的损失函数是:
其中是权重系数。值得注意的是,在LLM的训练中,熵正则项(Entropy Bonus)有时会被省略,因为KL惩罚已经提供了足够的正则化效果,防止策略坍缩成确定性分布。如果加入熵正则项,完整的目标函数为:
其中熵项定义为:
第五步:迭代与更新
完成个epoch的优化后,我们将更新后的策略设为新的旧策略:。然后回到第一步,重新采样数据,开始新一轮的训练循环。这个过程会持续进行,直到模型收敛或达到预设的训练步数。在实际训练中,每个PPO迭代(称为一个“rollout”)通常包含2048或更多个生成步骤,然后数据会被分成多个mini-batch进行多轮优化。这种设计——在同批数据上多次优化——正是PPO区别于传统On-Policy算法的关键,它大幅提高了数据利用效率。但同时,因为策略在优化过程中会发生变化,所以需要在下一次采样前更新“旧策略”的快照。
为什么LLM中的PPO训练如此困难
理解了PPO的具体流程后,我们不难发现为什么在LLM中应用PPO比在传统强化学习场景中更具挑战性。
- 长序列问题:LLM的一步是一个token,一个完整的回答可能有1000个token,这意味着horizon长度。误差累积和梯度传播非常深,这给训练稳定性带来了巨大挑战。
- 显存爆炸:你需要同时在显存中加载四个大模型(Actor, Reference, Critic, Reward)。虽然Reference和Reward模型不需要梯度更新,但它们仍然占用大量显存。在70B参数规模的模型上,即使是最先进的GPU也无法在单卡上完成这个任务,通常需要使用DeepSpeed ZeRO-3(将模型参数分片到多张GPU上)或PP(Pipeline Parallel,流水线并行)等分布式训练技术。
- 奖励稀疏问题:真正的Reward Model评分只在最后一步出现,前面的所有步骤的奖励全靠KL惩罚和Critic的价值估计来“推测”。这使得Critic的准确性变得至关重要,如果Critic预测不准,整个优势估计就会产生偏差。
- 训练效率问题:与传统强化学习可以在模拟器中快速生成百万级样本不同,LLM的每个生成步骤都需要经过完整的前向传播,计算成本极高。
这些因素共同解释了为什么PPO训练LLM需要如此大量的计算资源,以及为什么近年来研究者们开始寻找替代方案(如DPO,Direct Preference Optimization),试图绕过RLHF的复杂流程。